Hart Lambur (hal2001@columbia.edu)
Blake Shaw (bs2018@columbia.edu)
Lawrence Wang (levity@gmail.com)
Columbia University
New York, NY 10027
CUtunes is a tool for exploring the music listening habits of the Columbia University community. We provide basic services, including lists of top 40 songs, albums, and artists being played, as well as compatibility ratings between users, and recommendations for new music.
With iPods now holding over 60 gigs of music (more than 25,000 songs) and the average college student having more than 1500 MP3s on their computer, music is becoming more accessible than ever before. No longer do college students have to fill their rooms with boxes of vinyl records or racks of CDs -- new technologies allow us to access a tremendous amount of music instantaneously. But this 'overload' of music presents an interesting problem: how is one supposed to organize, explore, or know how to expand their music collection?
To help solve this problem, we propose a new way to explore music in a small community, such as Columbia University. CUtunes offers a real-time 'Top 40' list, showing the most popular songs, albums and artists being played by students on their computers and iPods. Furthermore, we compare the music libraries of our users to calculate a 'compatibility' rating identifying users with similar musical tastes and providing recommendations for new music based on this similarity.
Accessibility is not the only benefit of a digital music format. For the first time we can collect precise data about the listening habits of a community. With this information, we can provide intelligent tools which can give music-listeners a better understanding of their musical tastes in a fashion which develops naturally out of a community of people exhibiting their musical preferences. The discovery of new music can be shifted away from the hands of advertisers, TV, and radio stations and can come from a more genuine source of information, the listening habits of the people of our community.
To demo the service, please log on to CUtunes.com and sign up. To read more about our implementation and how our service works, read on below.
Aggregating music data to form real-time, community-based popularity charts and recommendations is a new idea not implemented elsewhere, but several interesting services do exist to help users 'explore' their musical collections. One of the most interesting is the Audioscrobbler service, developed out of a similar college project at a London area university. From the Audioscrobbler site:
The Audioscrobbler service offers some similar feature to our project, but is fundamentally different in both its implementation of goals. Audioscrobbler gets its data by polling the music a user is currently listening to (using a daemon running on the user's computer). This requires the user to run the service for quite a while before meaningful 'neighbors' can be found, and additionally, the service will never see music that you haven't played since starting the service, or get playcount data from your iPod or MP3 player.
Audioscrobbler is 'user-centric' in its implementation. Each user's statistics page (for an example, you can see Hart Lambur's page here) lists user specific information and doesn't tie into a real community. CUtunes is fundamentally different because each user is part of an actual community, and each user's playcounts contribute to the musical taste of that community. Audioscrobbler is quite good at offering recommendations, but its global scope lacks the intimacy that our community-centered service enjoys.
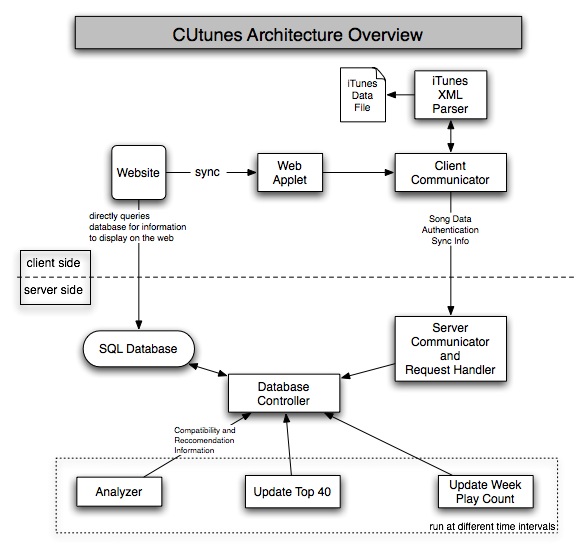
The CUtunes service involves three basic components (~3777 lines of code):
A website to display information to CUtunes users. The website is run on a standard LAMP (Linux, Apache, MySQL, Python/Perl/PHP) software stack, that provides great performance on a well-supported (and completely free) open-source platform. It is described in the Client View section below.
A client program to send music information to the CUtunes server. Our client program gathers the information contained in our user's MP3 libraries and send it to the CUtunes server. We support Apple's iTunes MP3 player exclusively, since iTunes stores all play count / play date in an easily accessible XML file. Implementation details and design decisions are described in the Client Update section below.
A server program to receive the user's information, calculate top 40 charts, generate recommendation, etc. The server is written in Java using Apache's XML-RPC implementation for message passing. The system is described in the Server Program section below.
When a user goes to CUtunes.com, the following components and technologies are involved:
The web pages are served by Apache 2 with mod_python, a module that embeds the interpreter for the Python programming language within Apache. Among other features, mod_python provides a way to mix HTML and Python in a single page, called Python Server Pages (PSP), using syntax similar to JSP. It also provides a session object, which we use to handle user login and logout. All this is entirely server-side, of course, requiring no special support from the end-user's web browser.
We use embedded Python in the pages of CUtunes.com to retrieve data on songs and users from our MySQL database, using the python module MySQLdb, which makes connecting to MySQL a simple matter. The data is then laid out in a readable manner with HTML, Javascript, and CSS.
More detail on the PSP files is in the Program Documentation section.
When initially designing the client architecture, we briefly considered writing a client that would display the user's top songs and other information directly on the desktop. However, it soon became apparent that writing a web-based system was the better option, for several reasons:
So we designed and implemented a system that is fully usable by any Columbia student with a modern browser and support for Java applets.
Python was chosen due to existing familiarity with the language and because we were under the impression that it has an extensive collection of third-party modules for interfacing with many different data formats easily and quickly. This turned out to be quite true at least in the case of python-ldap, which required only a small amount of time to understand and use, even with no prior experience using LDAP.
It is also interesting to note, though perhaps common enough now that it is taken for granted, that all the technologies used to implement this project are freely available. As mentioned earlier, the web frontend is constructed from a LAMP (Linux-Apache-MySQL-Python) stack, all of which are open source projects. Our server is a 1Ghz VIA Epia running Gentoo Linux.
The CUtunes client is the foundation of our system, as it is the sole means by which we acquire music data. In designing the client we knew it was essential that the software work flawlessly and easily, so as many people as possible would be tempted to sign up for our service and continue to use our service.
Early on we made the decision that CUtunes would support Apple's iTunes MP3 player exclusively. We made this choice for a number of important reasons. We believe that iTunes is the best and most popular MP3 player used in the Columbia community. Furthermore, the number of student with iPods (which requires iTunes) continues to grow, and we wanted to be sure to capture the musical taste of those users. iTunes stores its music database (including play counts and last played dates) in an easily accessible XML file (and this XML file is updated with play-counts from iPods whenever an iPod is 'synced' with its host computer). Apple's use of vanilla XML makes acquiring iTunes data relatively simple.
To read the iTunes XML file, we had to decide on an XML parser and implementation. Due to the potentially large size of the XML file (users with ~10,000 songs have XML files of ~15 MB) we knew using a DOM parser to load the XML into memory didn't make much sense, especially since we didn't need to modify the DOM tree. Instead, we chose the standard SAX (Simple API for XML) parser. The SAX parser allows for only serial access (which is all we need), allowing for much faster reads with lower memory overhead. Performance comparisons showed the SAX parser to be much more effective than DOM.
The SAX parser has efficient, well-supported implementations in all the major languages. For quite a while we debated between using Java or C/C++ for our client software. Initially, we thought that C/C++ would allow for the cleanest, easiest-to-use client software with the nicest GUI, even though using C/C++ would require that we support two codebases, one for Mac OS X and one for Windows XP. However, we were more comfortable in Java, and quite liked Java's SAX implementation. Because of this, early in the semester we decided that we would start in Java and move to C/C++ as required. However, Java has worked quite well and, due to some other consideration/design choices discussed below, we have since dropped our plans for a C/C++ client.
We need a flexible system to transfer the information that our client program gathers to the CUtunes server. Initally we looked at many options: Java ServerSockets, J2EE, CGI GET and POST, REST, FTP, XML-RPC, SOAP. Because we potentially wanted to move to a C/C++ client at a later date, the Java solutions were crossed out. Furthermore, we didn't think GET/POST or REST would be robust enough for the amount of transfer. In the end, XML-RPC seemed to be the perfect lightweight and flexible protocol, which would be easier to implement than SOAP.
Nice XML-RPC packages exist for both C/C++ and Java, although we were particularly impressed with Apache XML-RPC and its robust yet simple Java implementation.
When the idea of using a Java applet first surfaced back in the project's infancy, we were turned off the idea because of bad applet experiences, ugly GUIs, and slow load times. We also thought applet security issues would restrict our ability to read files on the user's computer. Instead we choose to write a Java application that could be wrapped in OS specific GUI code, and produced a pretty Mac OS X version.
When it came time to write a PC version, however, we played with the applet idea again. After investing considerable time researching the security restrictions, we realized applets can read from a user's computer if the JAR file is signed with a security certificate that the user must accept. We also experienced a remarkably better applet experience than we had previously experiences -- modern JVMs are much faster and new browsers cache the applet. Now we have implemented a very simple and clean applet, which works quite well on both the Mac OS X and Windows XP platforms, and integrates seamlessly into the web interface, as shown below. While the Mac OS X application is still available, the applet is now the main way users update their data.

After making our design choices the client implementation was rather simple. Three Java classes form the com.cutunes.client package:
The CUtunes server software is the backbone of our system. It must reliably receive large amounts of XML-RPC data and insert them into our database efficiently and effectively. Below we detail some of the major design choices and implementation details.
We used the same Apache XML-RPC package the client software use for our server backend. The Apache package offers a number of flexible options for starting an XML-RPC server -- the package can be used within a J2EE/JSP Application Server, or run on its own as a flexible, lightweight XML-RPC server. We choose to run the server as a stand-alone Java application, and use JDBC to connect to our database (running on the same machine).
The XML-RPC server is started in a very simple ServerCommunicator java class and uses a RequestHandler to receive XML-RPC messages. The API RequestHandler uses is comprised of four very simple methods:
The main method is of course bulkLoadSongs() which sends a group of SongData objects to the server. SongData is a simple abstraction which holds all relevant data pulled from the iTunes XML file for each track.
In the first few versions of our application, we generated all the charts dynamically, upon page view. However, as the number of users and therefore the size of our database increased, this dynamic regeneration became time-consuming, not to mention redundant, since the charts only change when people sync their data, which is less frequently than they refresh a page.
To solve this problem, we decided to only update the community charts every hour, then cache the new charts in the database so that they can be retrieved with a simple select, as opposed to requiring the whole has_song table to be sorted and taking the topmost results.
The same performance problem comes up with generating recommendations and compatibility ratings, in fact to a larger extent, since they are produced by looking through more data. These charts are now generated nightly.
Thirdly, our week play count values must be reduced heuristically, which is a somewhat unfortunate compromise, but a better solution than not changing them at all, which would lead to behavior such as a person having the same apparent "play count this week" for certain songs, when in fact the person has stopped using the service entirely. We therefore decrement the week play counts nightly as well.
We schedule these tasks by using the well-known Unix scheduling daemon, cron (specifically vixie-cron). Cron in turn calls upon three ant tasks specified in our build.xml file: cache.top40, analyze, update.playCountWeek. Ant automatically compiles files as necessary, sets environment variables and classpaths, and runs the appropriate Java classes. The Java classes in turn interact with MySQL via JDBC to make updates.
After defining the API and database scheme, the Server implementation was relatively painless. The following classes define the com.cutunes.server package. Class names below link to the Javadoc.
One goal for CUtunes is to use collected data to provide a 'compatibility' rating between all users, and then to use this rating to calculate recommendations for new music for each user.
The data can be thought of as a NxD matrix where N is the number of users and D is the number of songs/albums/artists. Each value of this matrix corresponds to how much a user plays a given item.
Our current implementation (in use now) focuses on calculating a similarity rating for each pair of users using the following method:
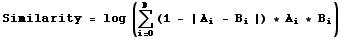
Where:
However, the problem of calculating compatibility between users can more accurately be thought of as calculating distances between two users in a D dimensional space. The closer two users are, the more compatible they are.
We have been experimenting with other metrics focusing on distance:
From intuition, although it is less mathematically rigorous, our current implementation seems to provide more accurate results then the Euclidean Distance metric. However KL divergence seems to produce the most accurate 'distances' between users. Currently we have these experimental techniques implemented only in MATLAB.
We have also been experimenting with ways to visualize compatibility of all users using Locally Linear Embedding. Here is a 'map' of CUtunes' users:
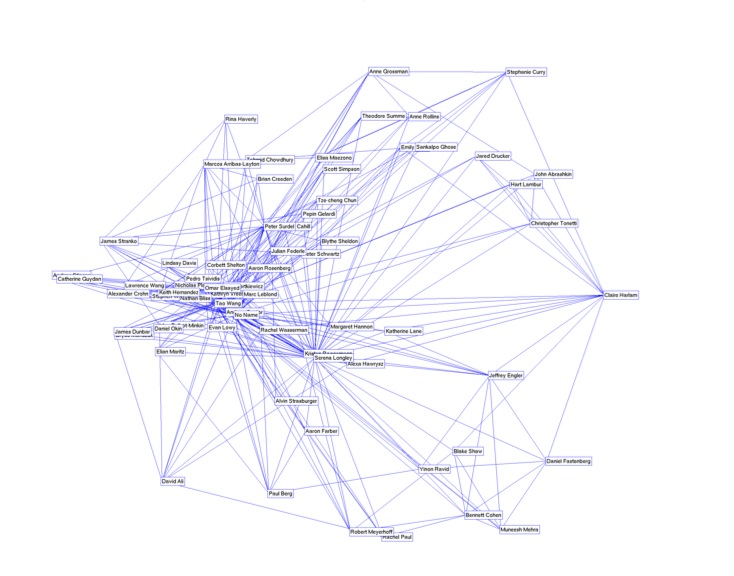
For more information about our experimental metrics for compatibility and visualizing this data, please see the following paper:
Machine Learning Techniques for Visualizing High-Dimensional Data
To provide recommendations for a user we find 10 items (songs, albums, and artists) not in the user's current library which have the highest recommendation score. The recommendation score is calculated by multiplying the similarity rating for another user by the percent they listen to an item. The algorithm finds music which you don't have that similar users to yourself play often.
Blake set up the initial XML-RPC interface, as well as Mac OS X client and first generation web applet. He also wrote the compatibility and recommendation service, the admin page, and worked with Hart on client/server communication and database integration.
Hart developed the SAX XML parser, wrote the second generation web applet, and did a lot of work on the DatabaseController and server back end. He also worked with the web interface developing the songinfo.psp page.
Lawrence wrote most of the Python, HTML, Javascript, and CSS, and designed the look & feel of the web frontend. He also handled the Linux server administration and some of the build automation, which involved configuring cron, GNU screen, ant, CVS, and mod_python.
...Professor Schulzrinne, for all your advice and support this semester.