Minimum Volume Embedding
 Here is a pre-final-version of my first published paper in Machine Learning. The following paper is written with Prof. Jebara at Columbia, and will be published at the AI and Statistics 2007 conference. How exciting!
Here is a pre-final-version of my first published paper in Machine Learning. The following paper is written with Prof. Jebara at Columbia, and will be published at the AI and Statistics 2007 conference. How exciting!Abstract:
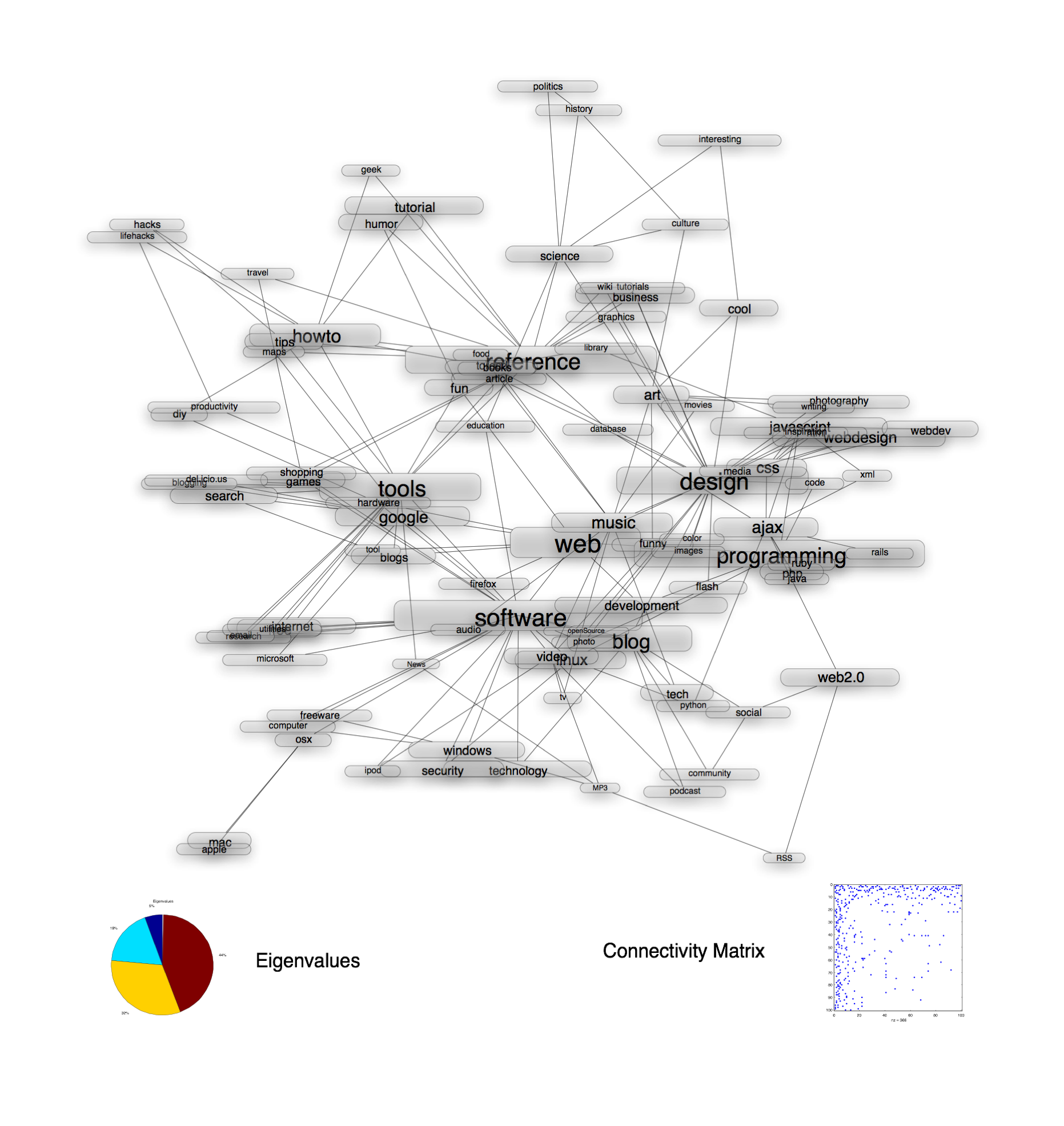
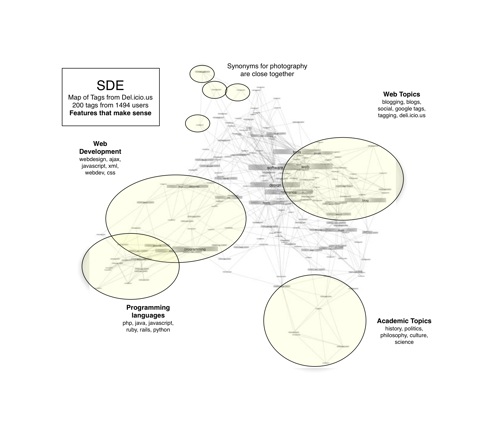
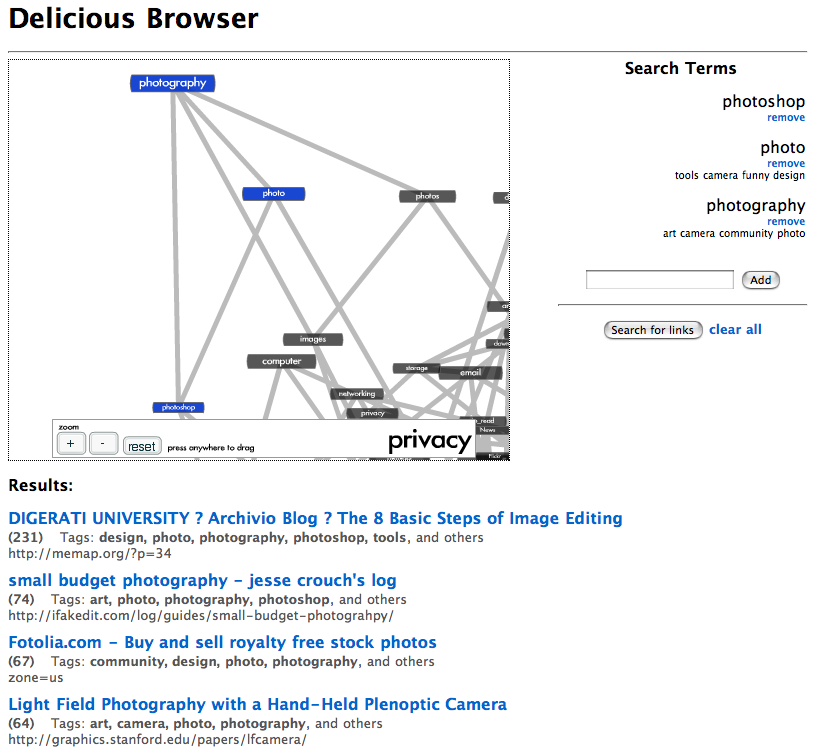
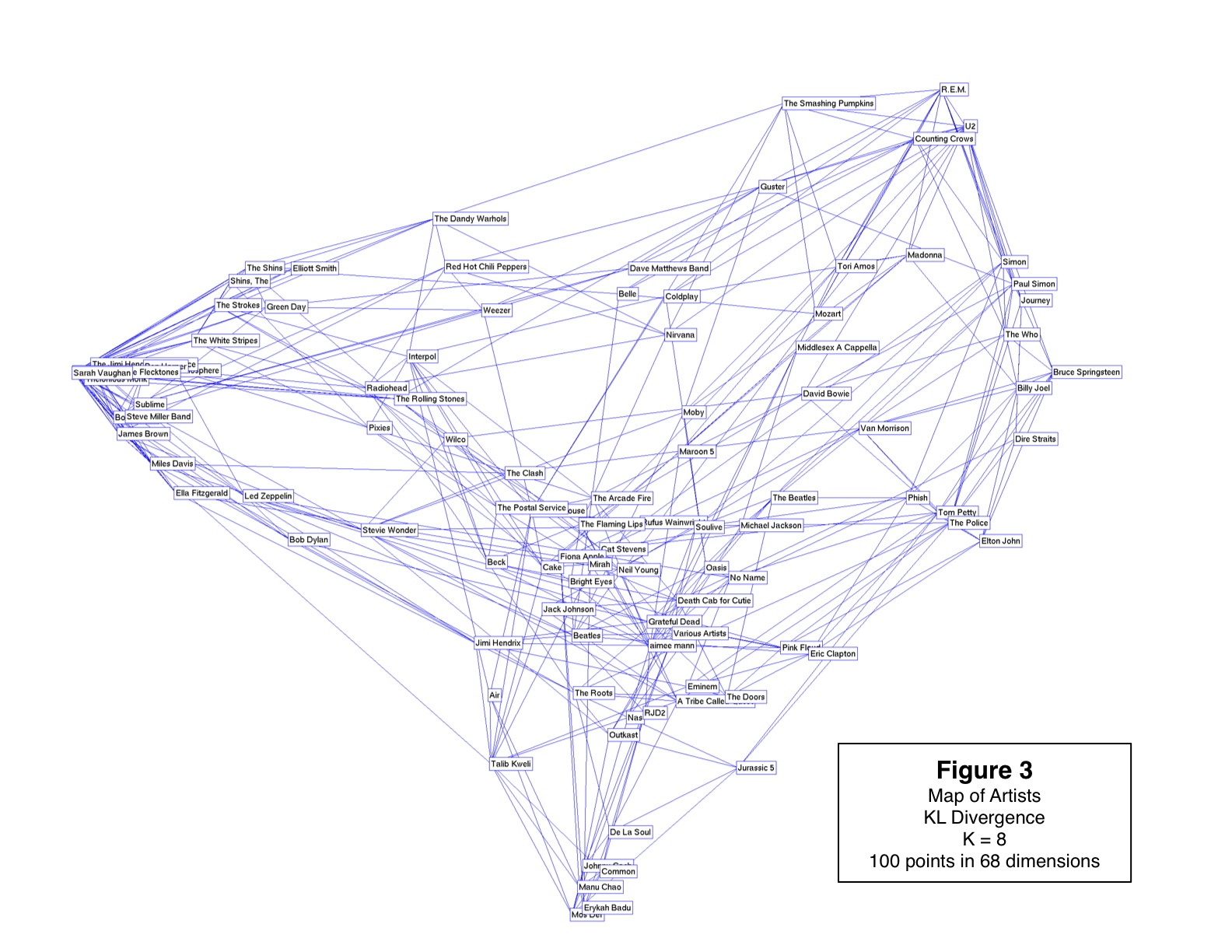
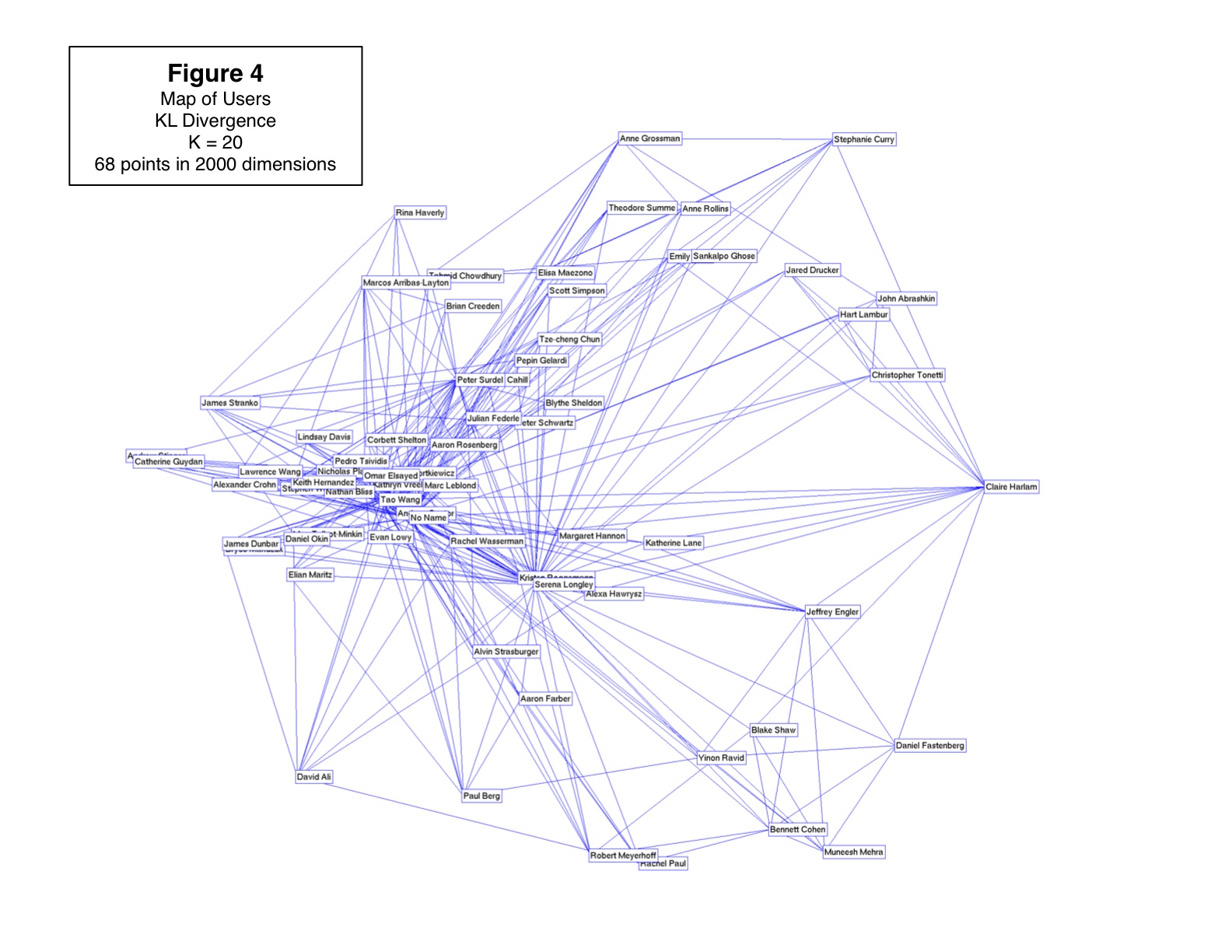
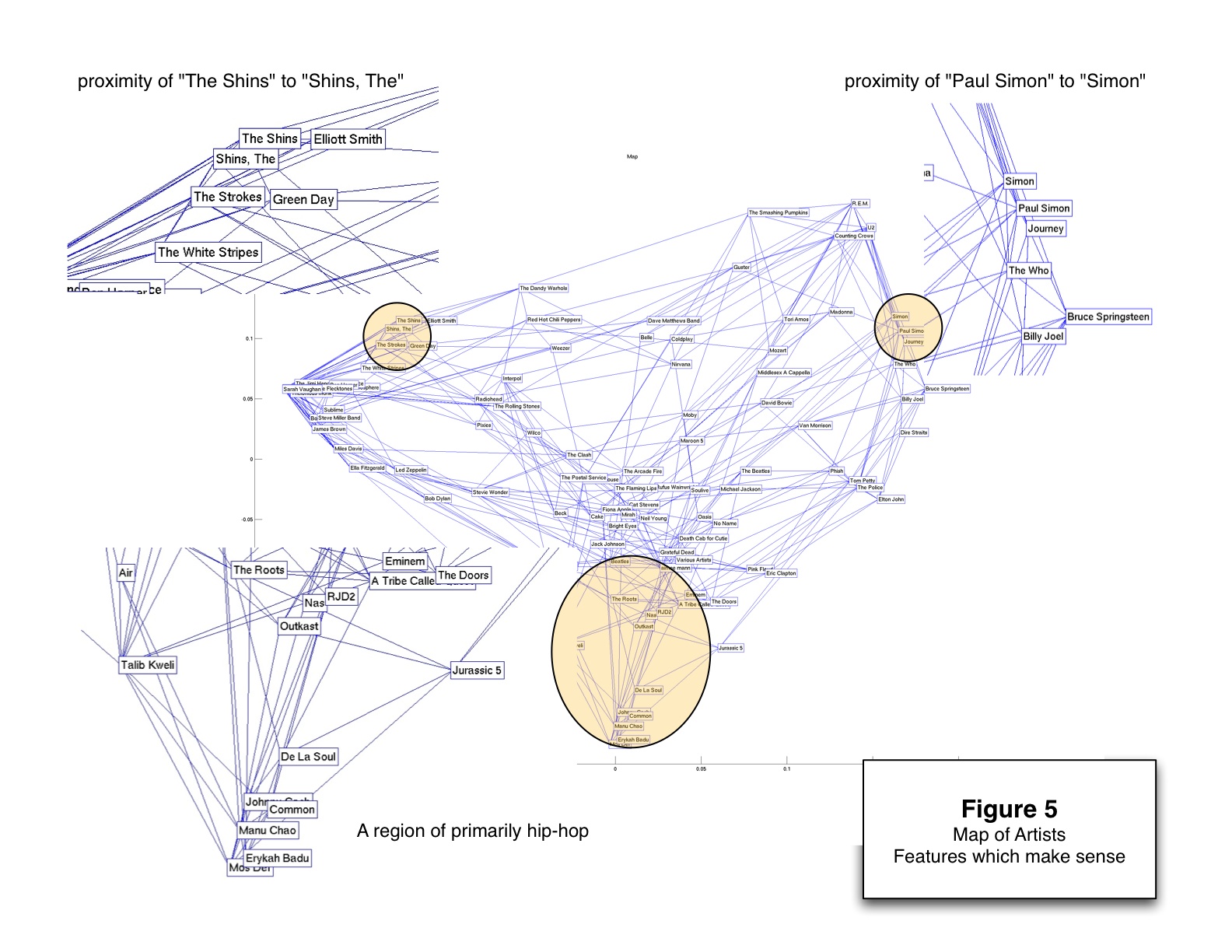
Minimum Volume Embedding (MVE) is an algorithm for non-linear dimensionality reduction that uses semidefinite programming (SDP) and matrix factorization to find a low-dimensional embedding that preserves local distances between points while representing the dataset in many fewer dimensions. MVE follows an approach similar to algorithms such as Semidefinite Embedding (SDE), in that it learns a kernel matrix using an SDP before applying Kernel Principal Component Analysis. However, the objective function for MVE directly optimizes the eigenspectrum of the data to preserve as much of its energy as possible within the few dimensions available to the embedding. Simultaneously, remaining eigenspectrum energy is minimized in directions orthogonal to the embedding thereby keeping data in a so-called minimum volume manifold. We show how MVE improves upon SDE in terms of the volume of the preserved embedding and the resulting eigenspectrum, producing better visualizations for a variety of synthetic and real-world datasets, including simple toy examples, face images, handwritten digits, phylogenetic trees, and social networks.
Minimum Volume Embedding (not final version)